Data Loading Pipeline¶
The ml4ir data loading pipeline is built on top of the tensorflow recommended data format called TFRecords. TFRecords is built using protocol buffers, which is a cross-language cross-platform serialization format for structured data. This makes it the best data format for search based applications like ranking, classification, etc.
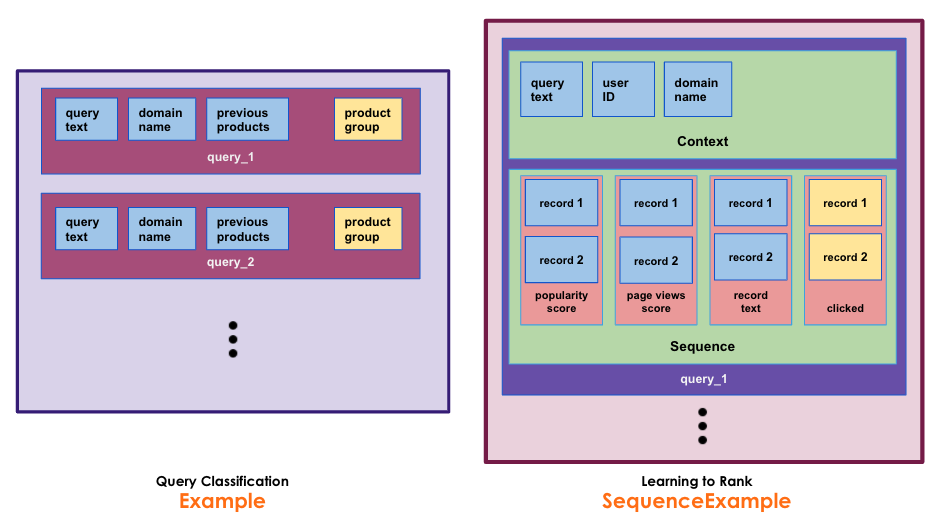
There are two types of TFRecord messages provided - Example and SequenceExample.
The first one that you see on the left is called Example. Here, we are using it to store sample query classification data. Each Example TFRecord message contains the features for a single query as key-value pairs. So the query text, domain name and previous products for a given query are stored in one single structure along with the product group, which is the classification label. We can build and store a TFRecordDataset as a collection of such Example messages.
The second type of protobuf message supported by TFRecords is called SequenceExample. SequenceExample contains two sub-types of features called as Context features and Sequence features (or feature lists). We use this to store data for models like Learning to Rank. We use context features to store features that are common across the query such as query text, domain name, user ID. Similar to Example, this is stored in one single sub-structure as key value pairs. Next we have the sequence features, which we use to store values for each feature as an ordered sequence corresponding to the documents. Here, we can see the features that are unique to each document such as popularity score, page views, record text. Finally, since the click label is also defined at a document level, we store that as a sequence feature as well.
Storing the Ranking data this way helps us achieve two things:
- Firstly, we now have a compact structured representation of data for ranking without redundant information as the query level features are stored only once per query as context features
- Secondly and more importantly, we now have a single object that contains all the query-document features for a given query. This means that we have all the information needed to learn complex ranking functions and define listwise losses for a given query without the need for any in-graph or preprocessing groupby operations.
This allows the storage to be efficient and training process to be fast.
The TFRecord data pipeline on ml4ir is configured out of the box for optimized data loading and preprocessing. The batches are lazy loaded and optimized by prefetching into memory for faster model training at scale. The serialized TFRecord messages are parsed and features are extracted based on the configuration specified in the FeatureConfig. ml4ir additionally applies preprocessing functions to the extracted features before feeding them as input into the model.