Saving ml4ir Models¶
ml4ir saves RelevanceModel in the SavedModel format. Doing so, allows us to add additional serving signatures to the persisted model. Serving signatures are pre and post processing wrappers for the blackbox tensorflow-keras model that is persisted along with the model. This allows us to write feature preprocessing logic at training time and be used at inference time. Additionally, these pre and post processing wrapper functions are persisted as tensorflow graph operations which allows for fast GPU executable serving time code.
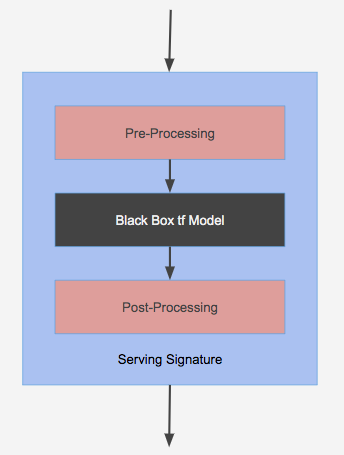
Saving the models with serving signatures allows ml4ir models to be served directly on TFRecord protocol buffer messages. The model can be saved with a serving signature that accepts a TFRecord proto message as a string tensor which can then be parsed to extract features. The features can then be preprocessed and fed into the model to compute the scores. These scores can optionally be post processed before sending it back to the serving model call. For example, this can be used for converting ranking scores from each document into ranks or sort documents based on the scores.
To save a RelevanceModel, use
relevance_model.save(models_dir=MODELS_DIR,
preprocessing_keys_to_fns={},
required_fields_only=True)
This saves
- a SavedModel with default serving signature that accepts feature tensors as key value inputs and returns the scores
- a SavedModel with TFRecord serving signature that accepts a TFRecord proto and returns the scores
- individual layer weights that can be used for transfer learning with other ml4ir models
Saving preprocessing logic¶
Optionally, we can save preprocessing functions in the SavedModel as part of the serving signature as well. This requires that the preprocessing function is a tf.function that can be serialized as a tensorflow layer.
relevance_model.save(
models_dir=MODEL_DIR,
preprocessing_keys_to_fns=custom_preprocessing_fns,
required_fields_only=True)