ml4ir - Machine Learning for Information Retrieval¶
ml4ir is an open source library for training and deploying deep learning models for search applications. ml4ir is built on top of python3 and tensorflow 2.x for training and evaluation. It also comes packaged with scala utilities for JVM inference.
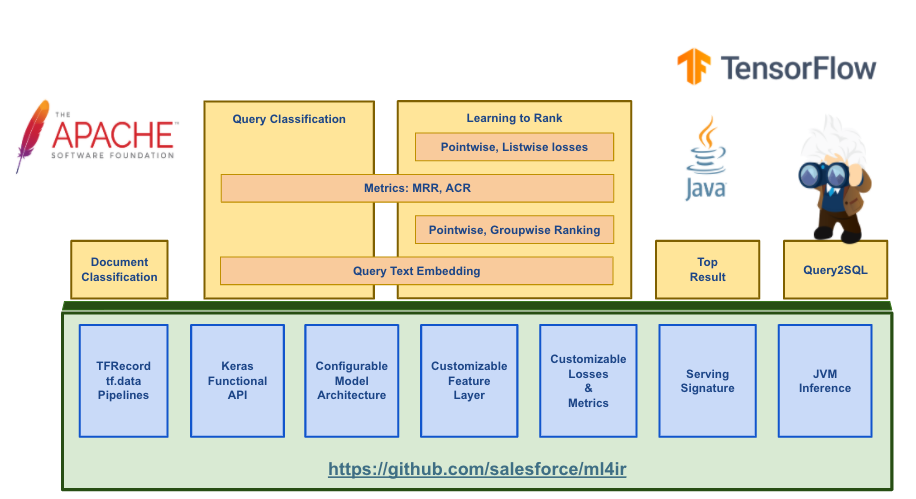
ml4ir is designed as modular subcomponents which can easily be combined and customized to build a variety of search ML models such as:
- Learning to Rank
- Query Auto Completion
- Document Classification
- Query Classification
- Named Entity Recognition
- Top Results
- Query2SQL
- add your application here
Motivation¶
Search is a complex data space with lots of different types of ML tasks working on a combination of structured and unstructured data sources. There existed no single library that
- provides an end-to-end training and serving solution for a variety of search applications
- allows training of models with limited coding expertise
- allows easy customization to build complex models to tackle a variety of problems in the search domain
- focuses on performance, robustness and offline-online feature parity
- enables fast prototyping
So, we built ml4ir.
Guiding Principles¶
Customizable Library
Firstly, we want ml4ir to be an easy-to-use and highly customizable library so that you can build the search application of your need. ml4ir allows each of its subcomponents to be overriden, mixed and match with other custom modules to create and deploy models.
Configurable Toolkit
While ml4ir can be used as library, it also comes prepackaged with all the popular search based losses, metrics, embeddings, layers, etc. to enable someone with limited tensorflow expertise to quickly load their training data and train models for the task of interest. ml4ir achieves this by following a hybrid approach which allow for each subcomponent to be completely controlled through configurations alone. Most search based ML applications can be built this way.
Performance First
ml4ir is built using the TFRecord data pipeline, which is the recommended data format for tensorflow data loading. We combine ml4ir’s high configurability with out of the box tensorflow data optimization utilities to define model features and build a data pipeline that easily allows training on huge amounts of data. ml4ir also comes packaged with utilities to convert data from CSV and libsvm format to TFRecord.
Training-Serving Handshake
As ml4ir is a common library for training and serving deep learning models, this allows us to build tight integration and fault tolerance into the models that are trained. ml4ir also uses the same configuration files for both training and inference keeping the end-to-end handshake clean. This allows user’s to easily plug in any feature store(or solr) into ml4ir’s serving utilities to deploy models in one’s production environments.
Search Model Hub
The goal of ml4ir is to form a common hub for the most popular deep learning layers, losses, metrics, embeddings used in the search domain. We’ve built ml4ir with a focus on quick prototyping with wide variety of network architectures and optimizations. We encourage contributors to add to ml4ir’s arsenal of search deep learning utilities as we continue to do so ourselves.
Contents¶
- Installation
- Quickstart
- Advanced Guide
- API Documentation
- Changelog
- [0.1.16] - 2023-02-06
- [0.1.15] - 2023-01-20
- [0.1.14] - 2022-11-18
- [0.1.13] - 2022-10-17
- [0.1.12] - 2022-04-26
- [0.1.11] - 2021-01-18
- [0.1.10] - 2021-12-29
- [0.1.9] - 2021-11-29
- [0.1.8] - 2021-10-21
- [0.1.7] - 2021-09-30
- [0.1.6] - 2021-07-16
- [0.1.5] - 2021-07-15
- [0.1.4] - 2021-06-30
- [0.1.3] - 2021-06-24
- [0.1.2] - 2021-06-16
- [0.1.1] - 2021-05-20
- [0.1.0] - 2021-03-01
- [0.0.5] - 2021-02-17
- License
- Contact Us